Case Study
How we migrated a Joomla academic archive without losing SEO
Preserving legacy URLs, indexed PDFs, and search visibility while rebuilding a broken academic archive into a faster, structured, AI-assisted publishing platform.
Client
International Journal of Ayurvedic & Herbal Medicine
Old legacy website vs new modern website
Old Legacy Website
Stack: Joomla CMS
URL: interscience.org.uk

Legacy Joomla archive site carrying years of research content, but with broken archive relationships, inconsistent article pages, and unstable performance.
New Modern Website
Stack: Next.js · Supabase · Vercel
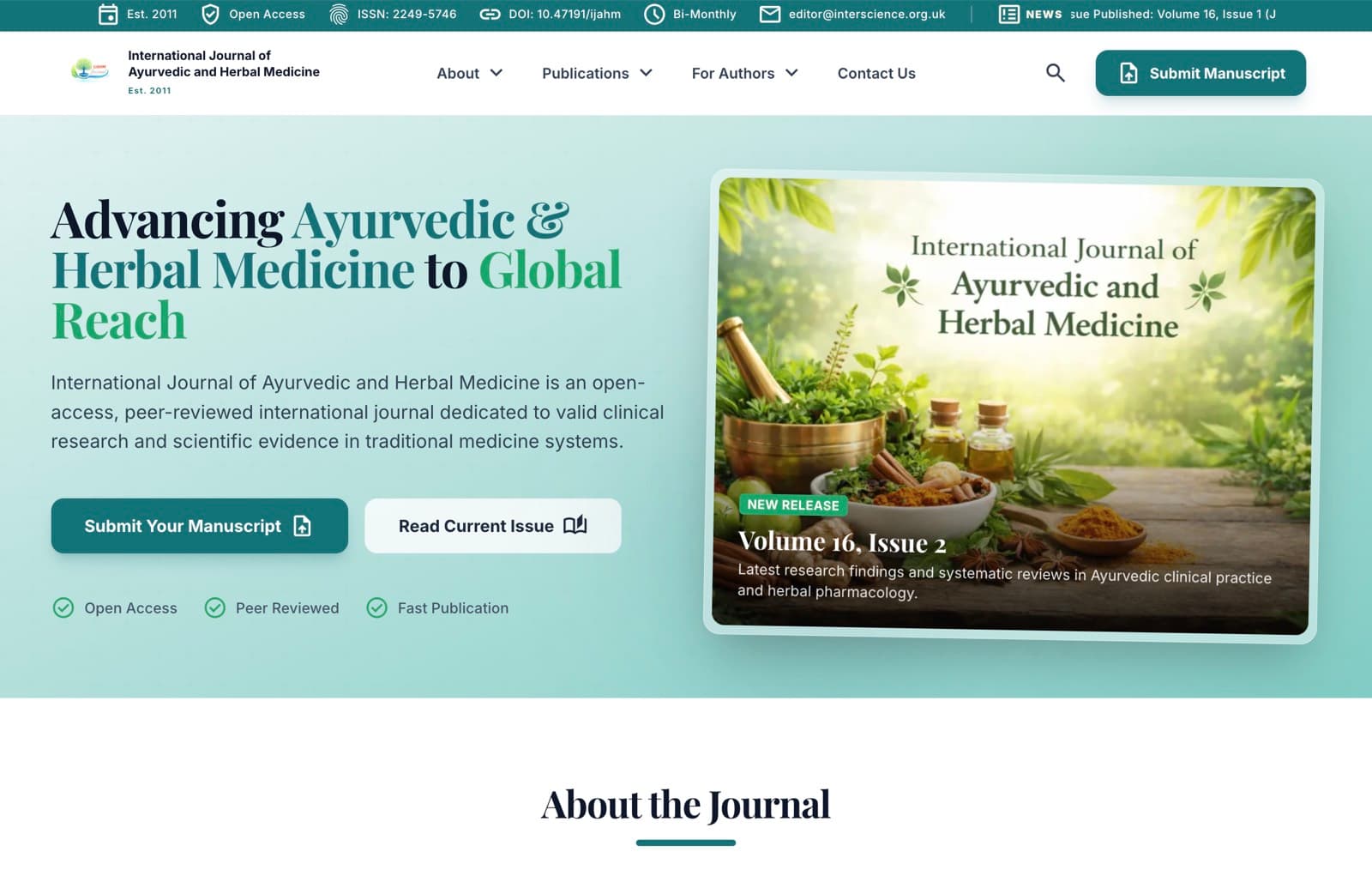
Modernized archive experience with structured navigation, maintainable architecture, and a faster foundation for search-friendly academic publishing.
The State of the Legacy Website
The legacy website was a Joomla-based academic journal archive with a deep volume → issue → article structure, hundreds of research PDFs, and years of indexed content already live in Google. It carried meaningful search visibility, but the underlying system had also accumulated serious technical and structural problems over time: duplicate slugs across different articles, missing issue/article relationships, PDF mismatches, inconsistent article page formats, and no strong information architecture to stitch the archive together. Search Console data showed that the site already had 200k+ search impressions and 1,800+ organic clicks, but also major indexing issues including duplicate canonical conflicts, broken pages, and large sets of crawled-but-not-indexed URLs. Performance was unstable enough that modern audit tools such as PageSpeed Insights could not reliably evaluate the old site, while direct performance testing showed extreme server delays.
The risk was clear: a careless rebuild would not just refresh the UI — it could erase years of search equity, break direct access to indexed research PDFs, and further damage an already fragile archive structure.
- •Legacy Joomla CMS running a large academic archive without strong structural intelligence
- •700+ pages with 500+ research articles and 700+ research PDFs
- •200k+ search impressions and 1,800+ organic clicks already tied to the archive
- •Deep volume → issue → article hierarchy but weak stitching between content objects
- •Duplicate slugs created URL conflicts and SEO ambiguity across articles
- •Articles missing from issues and volumes making archive navigation unreliable
- •PDF/article mismatches where some articles had no PDF page and some PDFs had no proper article page
- •Inconsistent article page formats because content was manually created across different layouts over time
- •No clear information architecture or breadcrumbs to connect volumes, issues, and articles for users or search engines
- •Hundreds of indexing issues including 679 duplicate canonical cases, 218 not found pages, 54 other 4xx pages, and 310 crawled-but-not-indexed pages
- •Legacy performance instability so severe that PageSpeed Insights often could not reliably evaluate the old site
The Challenge
This was not a simple redesign. The site had real search traffic, globally indexed article PDFs, and archive pages that readers and researchers were already using. Search Console data showed 200k+ impressions and 1,800+ clicks, with several PDF URLs among the top-performing pages. At the same time, the legacy setup had major indexing issues: 679 duplicate canonical cases, 218 not found pages, 54 other 4xx pages, and 310 crawled-but-not-indexed pages. The CMS was also not structurally reliable: duplicate slugs were assigned to different articles, articles were missing from issues and volumes, some article pages had no PDF, some PDFs had no proper article page, and the archive lacked breadcrumbs and coherent information architecture. The migration had to modernize the platform without breaking the URLs, PDFs, content relationships, and archive paths that search engines and readers already relied on.
Impact: the migration had to repair structure, preserve discoverability, and modernize performance without losing SEO equity or document access.
Site Scale
This was a content-heavy research archive, not a brochure site. The migration had to account for article pages, issue structures, direct PDF discovery in Google, and long-tail academic queries already driving real traffic.
- •700+ pages
- •500+ research articles
- •700+ research PDFs
- •200k+ search impressions
- •1,800+ organic clicks
- •80+ journal issues
Migration Approach
We treated the migration as an intelligence problem first and a build problem second. Search Console gave us a blueprint of what Google already cared about, while archive analysis exposed where the legacy CMS had failed to maintain content relationships. From there, we rebuilt the archive model, preserved search-sensitive URLs, and created a foundation for both structured discovery and future publishing speed.
- •Audited the archive using Search Console, crawl data, and legacy CMS analysis to identify what Google and users already depended on
- •Prioritized high-risk URLs, especially indexed research PDFs and long-tail article paths, for strict preservation
- •Resolved archive integrity problems such as duplicate slugs, missing issue/article relationships, and broken PDF-page connections
- •Created database-backed URL mapping and legacy path bridging for continuity across old and new systems
- •Used Joomla API data and structured extraction to preserve article metadata fidelity while rebuilding the archive model
- •Rebuilt the publishing workflow with an admin panel that can create structured article entries from PDFs in seconds
Architecture
The new platform was designed to keep the archive fast, maintainable, SEO-safe, and operationally easier to publish on at scale.
- Frontend: Next.js
- Database: Supabase
- Hosting: Vercel
The rebuilt system uses structured content models for volumes, issues, articles, and PDFs; database-backed legacy URL mapping; Incremental Static Regeneration for large archive scale; and a cleaner publishing foundation that supports AI-assisted article creation from research PDFs.
Results
The outcome was not just a better-looking site. It was a repaired archive, a dramatically more maintainable publishing system, and a migration that respected the search, citation, and document footprint the journal had already built.
Legacy URLs were preserved or safely bridged, including irregular historical PDF paths
Indexed PDF access was maintained across a research library of 700+ documents
Archive structure was reconstructed into a clean volume → issue → article hierarchy
Search-sensitive content was protected during rebuild despite major pre-existing indexing issues
Performance improved from ~36.6s TTFB / 38s FCP on the legacy site to ~1.1s FCP on desktop and ~3.2s FCP on mobile on the modern site
Publishing workflow shifted from manual article creation to AI-assisted PDF-to-article publishing in seconds
Platform migration moved from a fragile legacy Joomla setup to a maintainable Next.js + Supabase + Vercel stack
Decision quality was driven by real search data, content relationships, and archive recovery needs rather than guesswork
The real value in a migration is not moving data. It is understanding what must be preserved — URLs, PDFs, metadata, and content relationships — before you rebuild.
Planning a Joomla or WordPress migration?
Start with a free migration audit and understand the SEO, URL, and archive risks before rebuilding your website.
Get Free Migration Audit